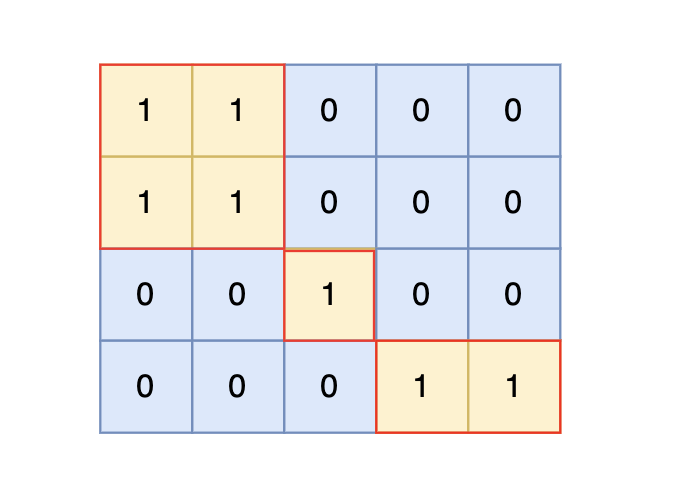
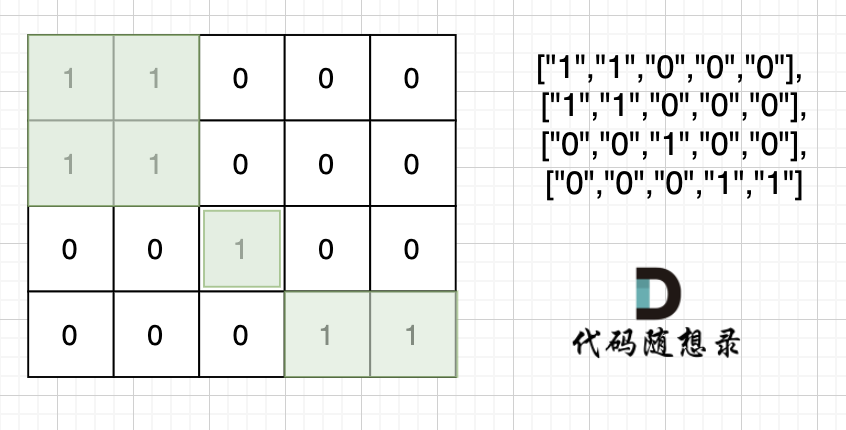
defdfs(graph, visited, x, y) -> int: # 注意,仅探索x,y的上、下、左、右相邻的区域 for i inrange(4): nextX = x + direction[i][0] nextY = y + direction[i][1] if nextX<0or nextX>=len(graph) or nextY<0or nextY >= len(graph[0]): continue if visited[nextX][nextY] == 0and graph[nextX][nextY] == 1: visited[nextX][nextY] = 1 dfs(graph, visited, nextX, nextY)
defmain(): n, m = map(int, input().split())
table = [] res = 0 for _ inrange(n): table.append(list(map(int, input().split())))
visited = [[0] * (m) for _ inrange(n)] for i inrange(n): for j inrange(m): if visited[i][j] == 0and table[i][j] == 1: visited[i][j] == 1 res += 1 # 把i,j附近相邻的区域(上、下、左、右相邻位置)全部标记为1(已经探索过) dfs(table, visited, i, j) print(res)
# 广搜索用队列会方便一些,但使用栈也可以 defbfs(graph, visited, x, y): from collections import deque
que = deque() que.append([x, y]) visited[x][y] = True
while que: curX, curY = que.popleft() for i, j in direction: nextX = curX + i nextY = curY + j if nextX<0or nextX>=len(graph) or nextY<0or nextY >= len(graph[0]): continue if visited[nextX][nextY] == 0and graph[nextX][nextY] == 1: visited[nextX][nextY] = 1 que.append([nextX, nextY])
defmain(): n, m = map(int, input().split())
table = [] res = 0 for _ inrange(n): table.append(list(map(int, input().split())))
visited = [[0] * (m) for _ inrange(n)] for i inrange(n): for j inrange(m): if visited[i][j] == 0and table[i][j] == 1: visited[i][j] == 1 res += 1 bfs(table, visited, i, j) print(res)
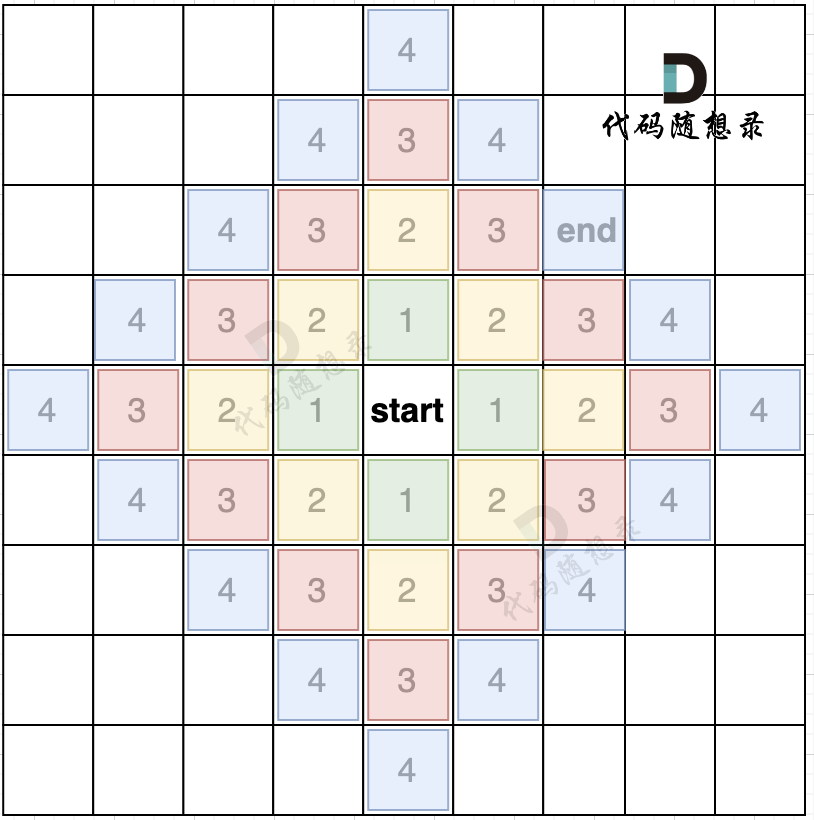
defdfs(graph, visited, x: int, y: int) -> int: area = 1 for i, j in direction: nextX = x + i nextY = y + j # 如果下一个节点不可达,直接跳过 if nextX < 0or nextY < 0or nextX >= len(graph) or nextY >= len(graph[0]): continue if graph[nextX][nextY] == 1and visited[nextX][nextY]== 0: visited[nextX][nextY] = 1 area += dfs(graph, visited, nextX, nextY) return area
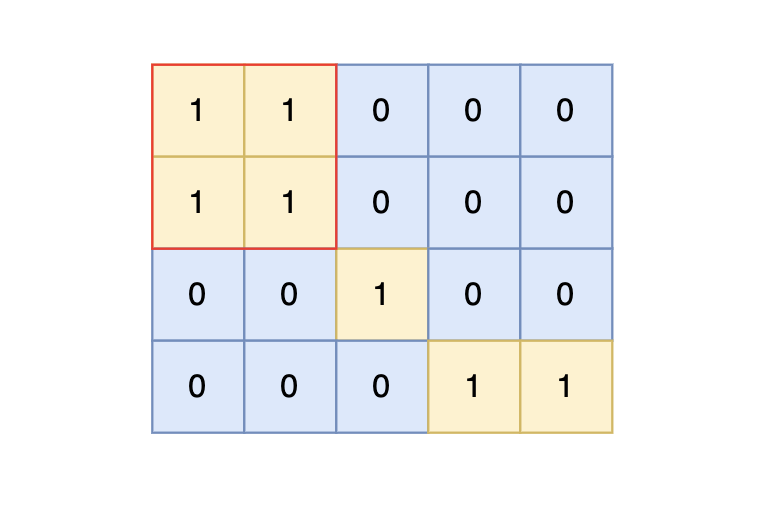
defmain(): n, m = map(int, input().split()) graph = list() for i inrange(n): graph.append(list(map(int, input().split()))) res = 0 visited = [[0] * m for _ inrange(n)] for i inrange(n): for j inrange(m): if graph[i][j] == 1and visited[i][j] == 0: visited[i][j] = 1 # 搜索每个岛屿上“1”的数量,然后取一个最大的。 res = max(dfs(graph, visited, i, j), res)
defdfs2(graph, visited, x: int, y: int) -> int: # 注意要写终止条件,并且返回0 if graph[x][y] == 0or visited[x][y] == 1: return0 # 单层逻辑 # 当前位置记录为已经去过 visited[x][y] = 1 # 初始化面积为1 area = 1 for i, j in direction: nextX = x + i nextY = y + j # 如果越界则跳过 if nextX < 0or nextY < 0or nextX >= len(graph) or nextY >= len(graph[0]): continue # 将面积增加 area += dfs2(graph, visited, nextX, nextY)
return area
defmain(): n, m = map(int, input().split()) graph = list() for i inrange(n): graph.append(list(map(int, input().split()))) res = 0 visited = [[0] * m for _ inrange(n)] for i inrange(n): for j inrange(m): if graph[i][j] == 1and visited[i][j] == 0: # visited[i][j] = 1 # 搜索每个岛屿上“1”的数量,然后取一个最大的。 res = max(dfs2(graph, visited, i, j), res)
area = 1 while que: curX, curY = que.popleft() for i, j in direction: nextX = curX + i nextY = curY + j
if nextX < 0or nextY < 0or nextX >= len(graph) or nextY >= len(graph[0]): continue if graph[nextX][nextY] == 1and visited[nextX][nextY] == 0: area += 1 visited[nextX][nextY] = 1 que.append([nextX,nextY]) return area
defmain(): n, m = map(int, input().split()) graph = list() for i inrange(n): graph.append(list(map(int, input().split()))) res = 0 visited = [[0] * m for _ inrange(n)] for i inrange(n): for j inrange(m): if graph[i][j] == 1and visited[i][j] == 0: visited[i][j] = 1 # 搜索每个岛屿上“1”的数量,然后取一个最大的。 res = max(bfs(graph, visited, i, j), res)