LeetCodeCampsDay53图论part04
继续使用深度/广度优先解决图的问题
其中105是有向图问题
110.字符串接龙
https://kamacoder.com/problempage.php?pid=1183
题目描述
字典 strList 中从字符串 beginStr 和 endStr 的转换序列是一个按下述规格形成的序列:
- 序列中第一个字符串是 beginStr。
- 序列中最后一个字符串是 endStr。
- 每次转换只能改变一个字符。
- 转换过程中的中间字符串必须是字典 strList 中的字符串,且strList里的每个字符串只用使用一次。
给你两个字符串 beginStr 和 endStr 和一个字典 strList,找到从 beginStr 到 endStr 的最短转换序列中的字符串数目。如果不存在这样的转换序列,返回 0。
输入描述
第一行包含一个整数 N,表示字典 strList 中的字符串数量。 第二行包含两个字符串,用空格隔开,分别代表 beginStr 和 endStr。 后续 N 行,每行一个字符串,代表 strList 中的字符串。
输出描述
输出一个整数,代表从 beginStr 转换到 endStr 需要的最短转换序列中的字符串数量。如果不存在这样的转换序列,则输出 0。
输入示例
1
2
3
4
5
6
7
8
| 6
abc def
efc
dbc
ebc
dec
dfc
yhn
|
输出示例
提示信息
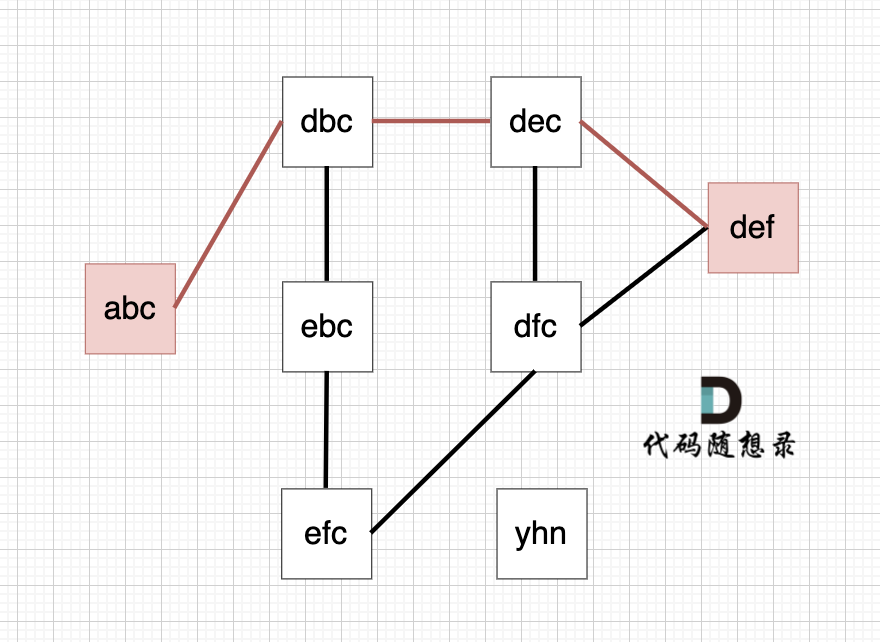
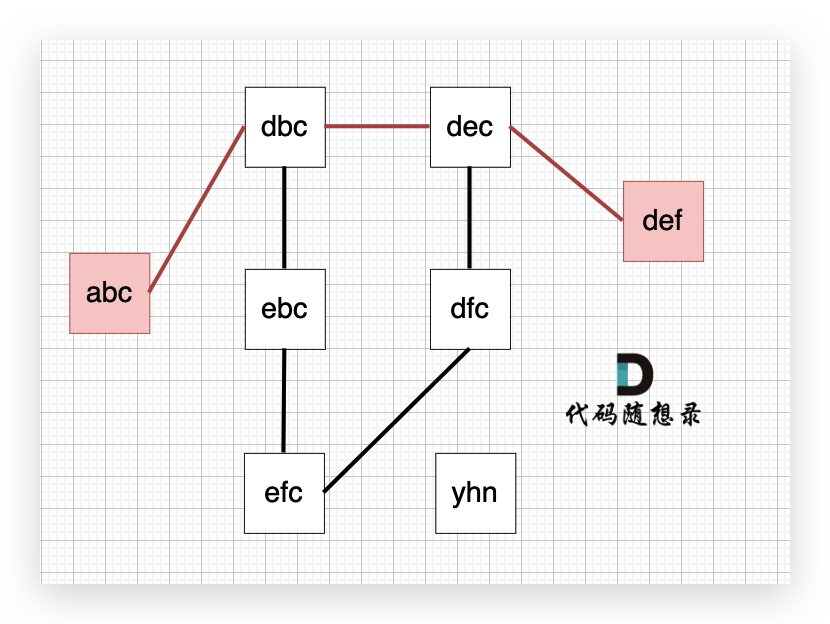
从 startStr 到 endStr,在 strList 中最短的路径为 abc -> dbc -> dec -> def,所以输出结果为 4,如图:

数据范围:
2 <= N <= 500
广度优先搜索思路
以示例1为例,从这个图中可以看出 abc 到 def的路线 不止一条,但最短的一条路径上是4个节点。
本题难点在于如何将输入变成一个无向图
第二难点在于求最短路径长度
解决思路
从beginStr开始(加入到广度优先遍历队列中)
从队列中先弹出curS,并对strList字符串遍历,如果curS与strList相差一个字母,则将strList添加到队列,并且记录从beginStr到达strList的步数,随后进行下一轮遍历;
本题需要有个辅助函数,用来判断两个字符串是否仅相差一个字母
广度优先搜索代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
def judge(s1, s2):
count = 0
Ls1 = len(s1)
for i in range(Ls1):
if s1[i] != s2[i]:
count += 1
return count == 1
def main():
n = int(input())
beginStr, endStr = input().split()
if beginStr == endStr:
print(0)
return
strList = list()
for _ in range(n):
strList.append(input())
visited = [0 for _ in range(n)]
que = [[beginStr, 1]]
while que:
curs, step = que.pop(0)
if judge(curs, endStr):
print(step + 1)
return
for i in range(n):
if visited[i] == 0 and judge(strList[i], curs):
visited[i] = 1
que.append([strList[i], step + 1])
if __name__ == "__main__":
main()
|
105.有向图的完全联通
题目描述
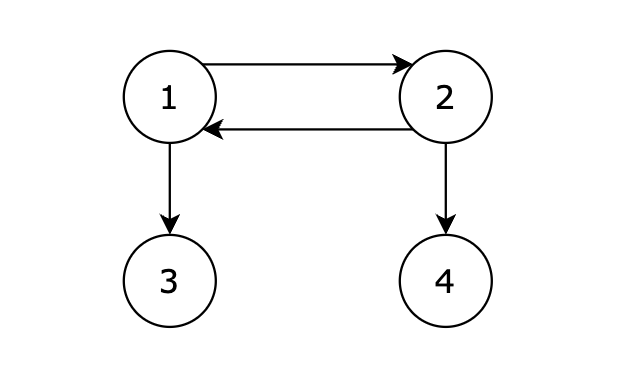
给定一个有向图,包含 N 个节点,节点编号分别为 1,2,…,N。现从 1 号节点开始,如果可以从 1 号节点的边可以到达任何节点,则输出 1,否则输出 -1。
输入描述
第一行包含两个正整数,表示节点数量 N 和边的数量 K。 后续 K 行,每行两个正整数 s 和 t,表示从 s 节点有一条边单向连接到 t 节点。
输出描述
如果可以从 1 号节点的边可以到达任何节点,则输出 1,否则输出 -1。
输入示例
输出示例
提示信息
从 1 号节点可以到达任意节点,输出 1。
数据范围:
1 <= N <= 100;
1 <= K <= 2000。
深度优先遍历的思路
本题可以先创建个邻接表,并对每个节点进行访问,最终判断是否存在未访问过的节点
使用深度优先遍历时(其实广度优先遍历也是一样的),需要
- 输入输出
输入应该为(graph, visited, 以及当前节点)
def dfs(graph, visited, p):
- 终止条件
dfs有两种写法,这里有一个很重要的逻辑,就是在递归中,我们是处理当前访问的节点,还是处理下一个要访问的节点。
本题中什么叫做处理,就是 visited数组来记录访问过的节点,该节点默认 数组里元素都是false,把元素标记为true就是处理 本节点了。
- 如果我们是处理当前访问的节点,当前访问的节点如果是 true ,说明是访问过的节点,那就终止本层递归,如果不是true,我们就把它赋值为true,因为这是我们处理本层递归的节点。
对应代码为
1
2
3
4
5
6
7
8
9
10
11
| def dfs(graph, visited, p):
if visited[p] == 1:
return
visited[p] = 1
for i in graph[p]:
if visited[i] == 0:
dfs(graph, visited, i)
|
- 如果我们是处理下一层访问的节点,而不是当前层。那么就要在 深搜三部曲中第三步:处理目前搜索节点出发的路径的时候对 节点进行处理。这样的话,就不需要终止条件,
而是在 搜索下一个节点的时候,直接判断 下一个节点是否是我们要搜的节点。
1
2
3
4
5
6
7
| def dfs(graph, visited, p):
for i in graph[p]:
if visited[i] == 0:
visited[i] = 1
dfs(graph, visited, i)
|
- 单层逻辑
本题的单层逻辑就是将节点设置为被访问过,不需要进行回溯(因为不用走回头路)
那什么时候需要回溯操作呢?
当我们需要搜索一条可行路径的时候,就需要回溯操作了,因为没有回溯,就没法“调头”, 如果不理解的话,去看我写的 0098.所有可达路径 的题解。
深度优先遍历代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
def dfs(graph, visited, p):
for i in graph[p]:
if visited[i] == 0:
visited[i] = 1
dfs(graph, visited, i)
def main():
n, k = map(int, input().split())
graph = [[] for _ in range(n + 1)]
visited = [0] * (n + 1)
visited[1] = 1
for _ in range(k):
start, end = map(int, input().split())
graph[start].append(end)
dfs(graph, visited, 1)
for i in range(1, n + 1):
if visited[i] == 0:
print(-1)
return
print(1)
if __name__ == "__main__":
main()
|
广度优先搜索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
def bfs(graph, path, p):
from collections import deque
que = deque()
que.append(p)
while que:
cur = que.popleft()
path.add(cur)
for i in graph[cur]:
que.append(i)
graph[cur] = []
return
def bfs2(graph, visited, p):
from collections import deque
que = deque()
que.append(p)
while que:
cur = que.popleft()
visited[cur] = 1
for i in graph[cur]:
if visited[i] == 0:
que.append(i)
def main():
n, k = map(int, input().split())
graph = [[] for _ in range(n + 1)]
for _ in range(k):
start, end = map(int, input().split())
graph[start].append(end)
visited = [0] * (n + 1)
visited[1] = 1
bfs2(graph, visited, 1)
for i in range(1, n + 1):
if visited[i] == 0:
print(-1)
return
print(1)
if __name__ == "__main__":
main()
|
106.岛屿的周长
题目描述
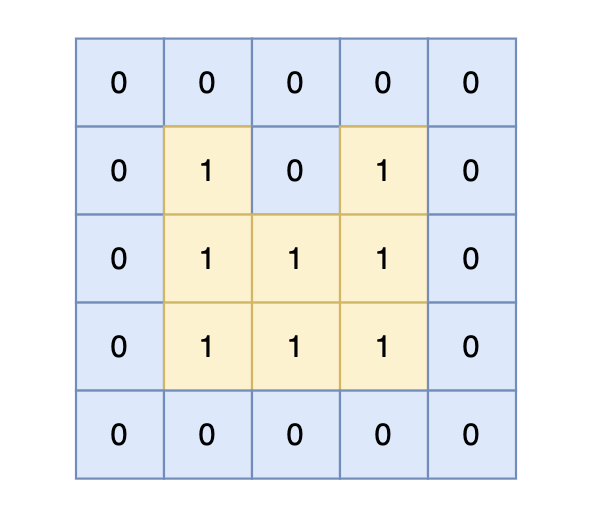
给定一个由 1(陆地)和 0(水)组成的矩阵,岛屿是被水包围,并且通过水平方向或垂直方向上相邻的陆地连接而成的。
你可以假设矩阵外均被水包围。在矩阵中恰好拥有一个岛屿,假设组成岛屿的陆地边长都为 1,请计算岛屿的周长。岛屿内部没有水域。
输入描述
第一行包含两个整数 N, M,表示矩阵的行数和列数。之后 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
输出描述
输出一个整数,表示岛屿的周长。
输入示例
1
2
3
4
5
6
| 5 5
0 0 0 0 0
0 1 0 1 0
0 1 1 1 0
0 1 1 1 0
0 0 0 0 0
|
输出示例
提示信息
岛屿的周长为 14。
数据范围:
1 <= M, N <= 50。
广度优先搜索思路
题目明确了岛被水包围,但要考虑岛周围是边界的问题
计算每块陆地的相邻块,相邻块有几个是水,则有周长就加几
遍历每一个空格,遇到岛屿则计算其上下左右的空格情况。
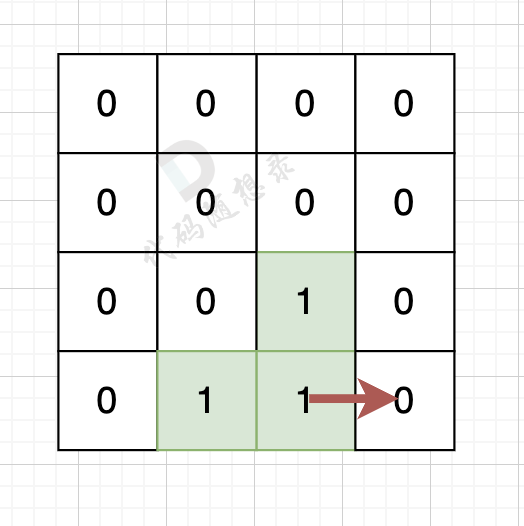
如果该陆地上下左右的空格是有水域,则说明是一条边,如图:
陆地的右边空格是水域,则说明找到一条边。
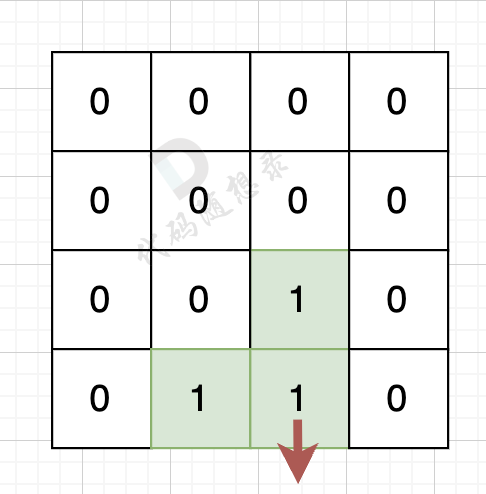
如果该陆地上下左右的空格出界了,则说明是一条边,如图:
该陆地的下边空格出界了,则说明找到一条边。
广度优先搜索代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
direction = [[0, 1], [1, 0], [-1, 0], [0, -1]]
def bfs(graph, visited, x, y) -> int:
from collections import deque
que = deque()
que.append([x, y])
visited[x][y] = 1
res = 0
while que:
curx, cury = que.popleft()
for i, j in direction:
nextx = curx + i
nexty = cury + j
if 0 <= nextx < len(graph) and 0 <= nexty < len(graph[0]):
if graph[nextx][nexty] == 0:
res += 1
if visited[nextx][nexty] == 0 and graph[nextx][nexty] == 1:
visited[nextx][nexty] = 1
que.append([nextx, nexty])
else:
res += 1
return res
def main():
n, m = map(int, input().split())
graph = list()
for _ in range(n):
graph.append(list(map(int, input().split())))
visited = [[0] * m for _ in range(n)]
res = 0
for i in range(n):
for j in range(m):
if visited[i][j] == 0 and graph[i][j] == 1:
res = bfs(graph, visited, i, j)
print(res)
if __name__ == "__main__":
main()
|