LeetCodeCampsDay57图论part07
LeetCodeCampsDay57图论part07
最小生成树算法
分别使用Prim算法和Kruscal算法
prim 算法是维护节点的集合,而 Kruskal 是维护边的集合。
53.寻宝(第七期模拟笔试)
题目描述
在世界的某个区域,有一些分散的神秘岛屿,每个岛屿上都有一种珍稀的资源或者宝藏。国王打算在这些岛屿上建公路,方便运输。
不同岛屿之间,路途距离不同,国王希望你可以规划建公路的方案,如何可以以最短的总公路距离将 所有岛屿联通起来(注意:这是一个无向图)。
给定一张地图,其中包括了所有的岛屿,以及它们之间的距离。以最小化公路建设长度,确保可以链接到所有岛屿。
输入描述
第一行包含两个整数V 和 E,V代表顶点数,E代表边数 。顶点编号是从1到V。例如:V=2,一个有两个顶点,分别是1和2。
接下来共有 E 行,每行三个整数 v1,v2 和 val,v1 和 v2 为边的起点和终点,val代表边的权值。
输出描述
输出联通所有岛屿的最小路径总距离
输入示例
1 | 7 11 |
输出示例
1 | 6 |
提示信息
数据范围:
2 <= V <= 10000;
1 <= E <= 100000;
0 <= val <= 10000;
如下图,可见将所有的顶点都访问一遍,总距离最低是6.

prim算法精讲
本题是最小生成树的模板题,那么我们来讲一讲最小生成树。
最小生成树可以使用prim算法也可以使用kruskal算法计算出来。
本篇我们先讲解prim算法。
最小生成树是所有节点的最小连通子图,即:以最小的成本(边的权值)将图中所有节点链接到一起。
图中有n个节点,那么一定可以用n-1条边将所有节点连接到一起。
那么如何选择这n-1条边就是最小生成树算法的任务所在。
例如本题示例中的无向有权图为:

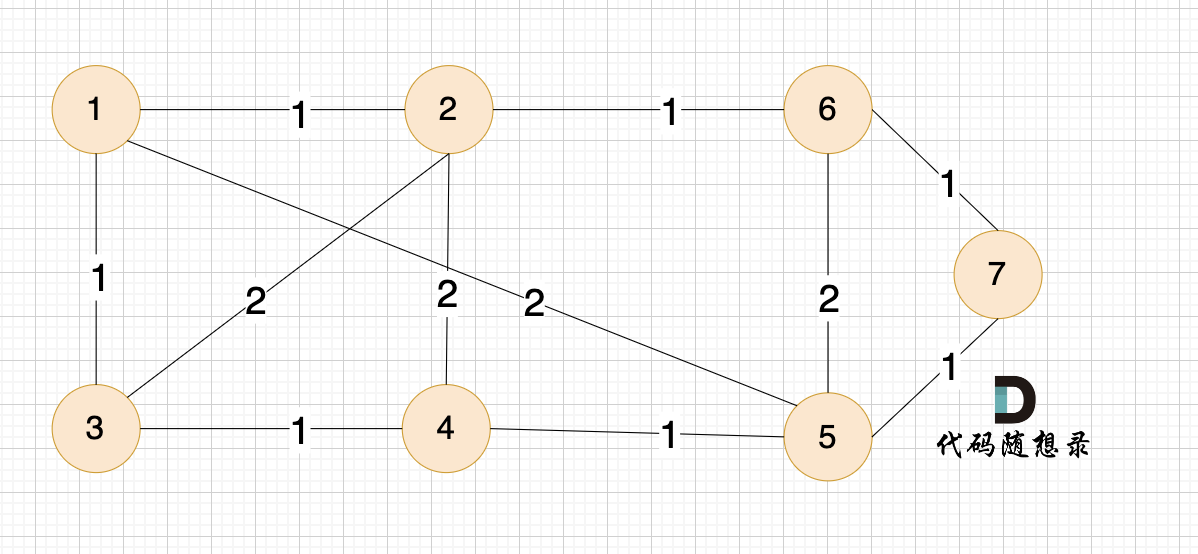
那么在这个图中,如何选取n-1条边使得图中所有节点连接到一起,并且边的权值和最小呢?
(图中为n为7,即7个节点,那么只需要n-1即6条边就可以讲所有顶点连接到一起)
prim算法是从节点的角度采用贪心的策略每次寻找距离最小生成树最近的节点并加入到最小生成树中。
prim算法核心就是三步,我称为prim三部曲,大家一定要熟悉这三步,代码相对会好些很多:
- 第一步,选距离生成树最近节点
- 第二步,最近节点加入生成树
- 第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
现在录友们会对这三步很陌生,不知道这是干啥的,没关系,下面将会画图举例来带大家把这prim三部曲理解到位。
在prim算法中,有一个数组特别重要,这里我起名为:minDist。
刚刚我有讲过“每次寻找距离最小生成树最近的节点并加入到最小生成树中”,那么如何寻找距离最小生成树最近的节点呢?
这就用到了minDist数组,它用来作什么呢?
minDist数组用来记录每一个节点距离最小生成树的最近距离。理解这一点非常重要,这也是prim算法最核心要点所在,很多录友看不懂prim算法的代码,都是因为没有理解透这个数组的含义。
接下来,我们来通过一步一步画图,来带大家巩固prim三部曲以及minDist数组的作用。
(示例中节点编号是从1开始,所以为了让大家看的不晕,minDist数组下标我也从1开始计数,下标0就不使用了,这样下标和节点标号就可以对应上了,避免大家搞混)
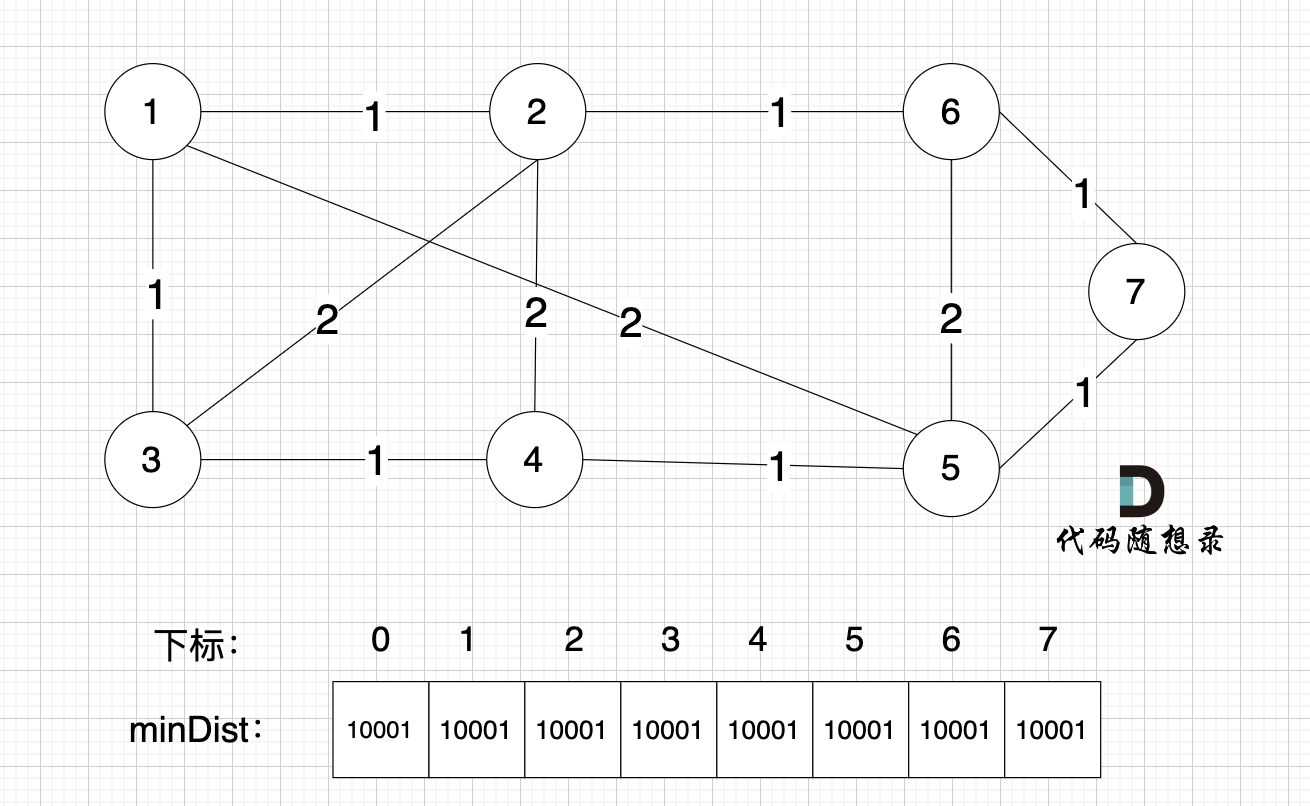
1 初始状态
minDist数组里的数值初始化为最大数,因为本题节点距离不会超过10000,所以初始化最大数为10001就可以。
相信这里录友就要问了,为什么这么做?
现在还没有最小生成树,默认每个节点距离最小生成树是最大的,这样后面我们在比较的时候,发现更近的距离,才能更新到minDist数组上。
如图:

开始构造最小生成树
2
1、prim三部曲,第一步:选距离生成树最近节点
选择距离最小生成树最近的节点,加入到最小生成树,刚开始还没有最小生成树,所以随便选一个节点加入就好(因为每一个节点一定会在最小生成树里,所以随便选一个就好),那我们选择节点1(符合遍历数组的习惯,第一个遍历的也是节点1)
2、prim三部曲,第二步:最近节点加入生成树
此时节点1已经算最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来,我们要更新所有节点距离最小生成树的距离,如图:

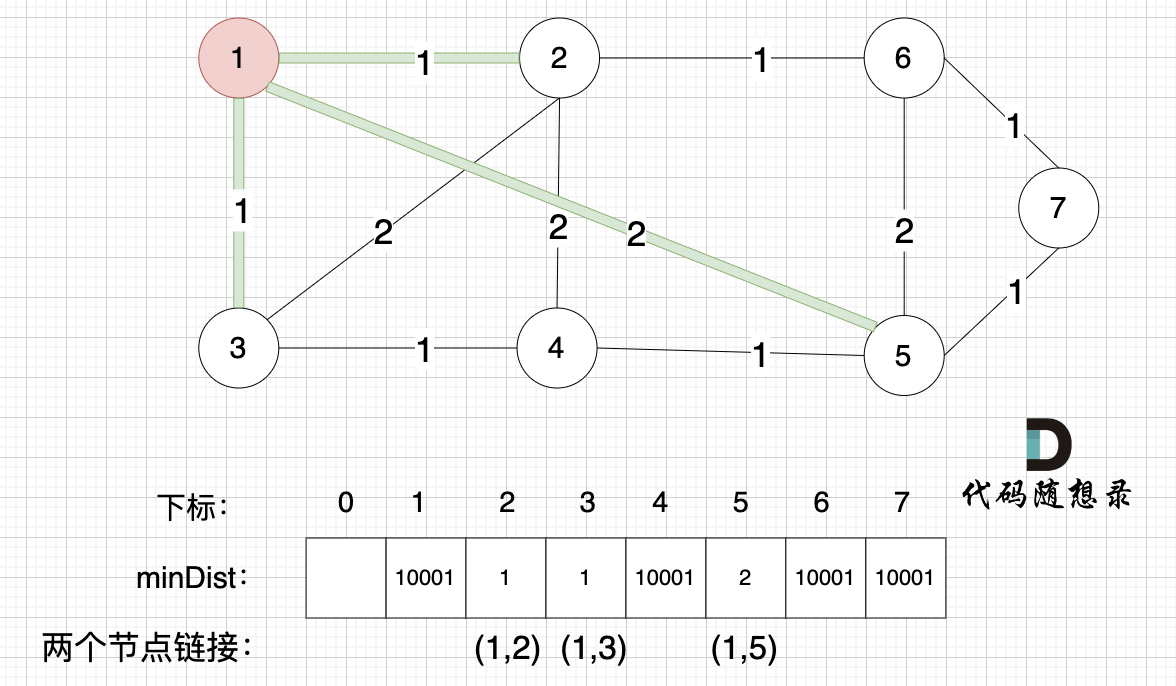
注意下标0,我们就不管它了,下标1与节点1对应,这样可以避免大家把节点搞混。
此时所有非生成树的节点距离最小生成树(节点1)的距离都已经跟新了。
- 节点2与节点1的距离为1,比原先的距离值10001小,所以更新minDist[2]。
- 节点3和节点1的距离为1,比原先的距离值10001小,所以更新minDist[3]。
- 节点5和节点1的距离为2,比原先的距离值10001小,所以更新minDist[5]。
注意图中我标记了minDist数组里更新的权值,是哪两个节点之间的权值,例如minDist[2]=1,这个1是节点1与节点2之间的连线,清楚这一点对最后我们记录最小生成树的权值总和很重要。
(我在后面依然会不断重复prim三部曲,可能基础好的录友会感觉有点啰嗦,但也是让大家感觉这三部曲求解的过程)
3
1、prim三部曲,第一步:选距离生成树最近节点
选取一个距离最小生成树(节点1)最近的非生成树里的节点,节点2,3,5距离最小生成树(节点1)最近,选节点2(其实选节点3或者节点2都可以,距离一样的)加入最小生成树。
2、prim三部曲,第二步:最近节点加入生成树
此时节点1和节点2,已经算最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来,我们要更新节点距离最小生成树的距离,如图:

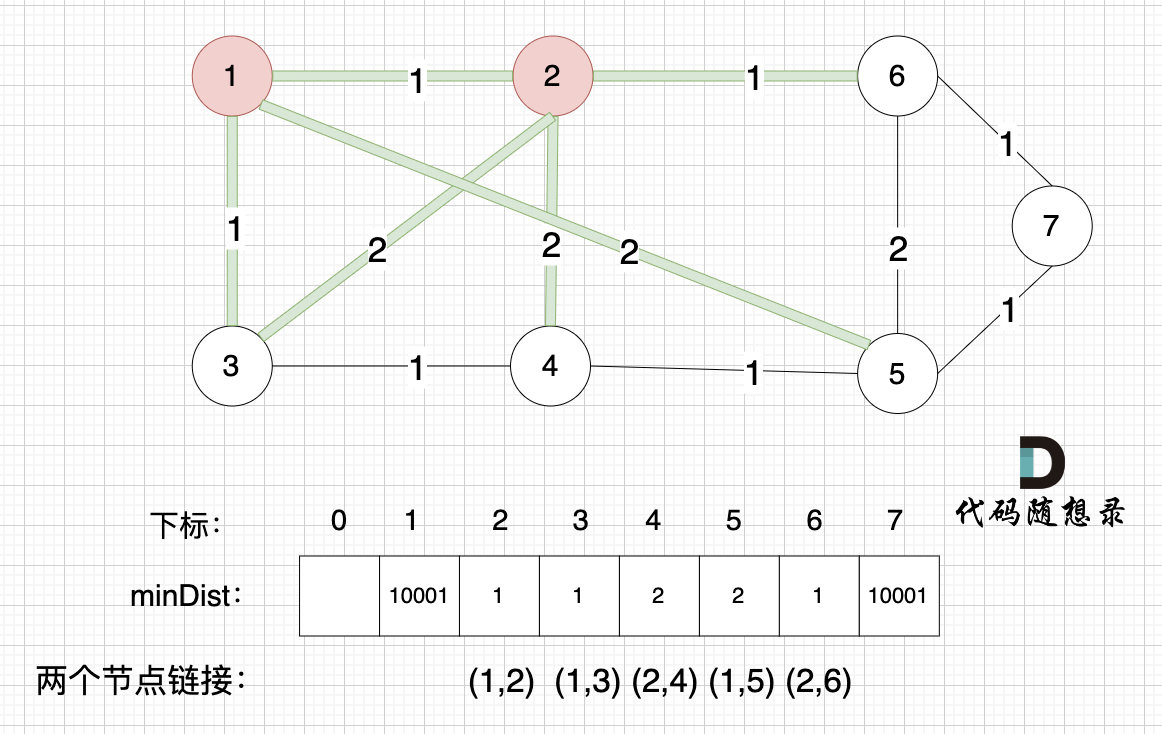
此时所有非生成树的节点距离最小生成树(节点1、节点2)的距离都已经跟新了。
- 节点3和节点2的距离为2,和原先的距离值1小,所以不用更新。
- 节点4和节点2的距离为2,比原先的距离值10001小,所以更新minDist[4]。
- 节点5和节点2的距离为10001(不连接),所以不用更新。
- 节点6和节点2的距离为1,比原先的距离值10001小,所以更新minDist[6]。
4
1、prim三部曲,第一步:选距离生成树最近节点
选择一个距离最小生成树(节点1、节点2)最近的非生成树里的节点,节点3,6距离最小生成树(节点1、节点2)最近,选节点3(选节点6也可以,距离一样)加入最小生成树。
2、prim三部曲,第二步:最近节点加入生成树
此时节点1、节点2、节点3算是最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来更新节点距离最小生成树的距离,如图:

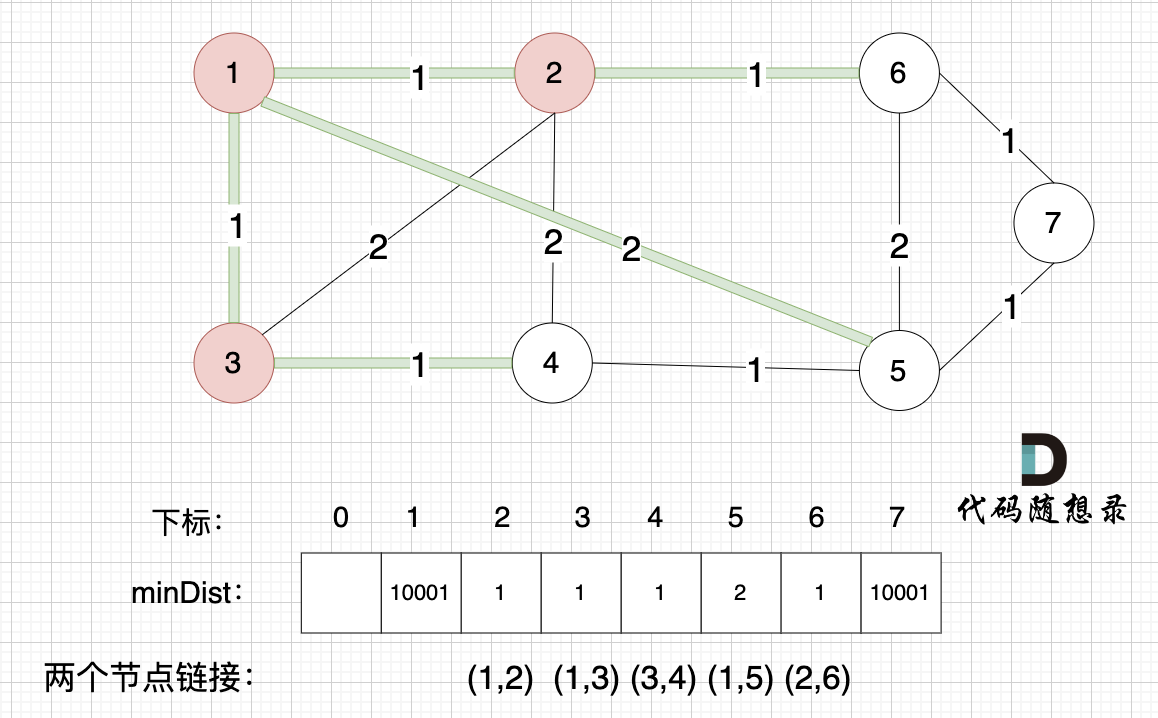
所有非生成树的节点距离最小生成树(节点1、节点2、节点3)的距离都已经跟新了。
- 节点4和节点3的距离为1,和原先的距离值2小,所以更新minDist[4]为1。
上面为什么我们只比较节点4和节点3的距离呢?
因为节点3加入最小生成树后,非生成树节点只有节点4和节点3是链接的,所以需要重新更新一下节点4距离最小生成树的距离,其他节点距离最小生成树的距离都不变。
5
1、prim三部曲,第一步:选距离生成树最近节点
继续选择一个距离最小生成树(节点1、节点2、节点3)最近的非生成树里的节点,为了巩固大家对minDist数组的理解,这里我再啰嗦一遍:

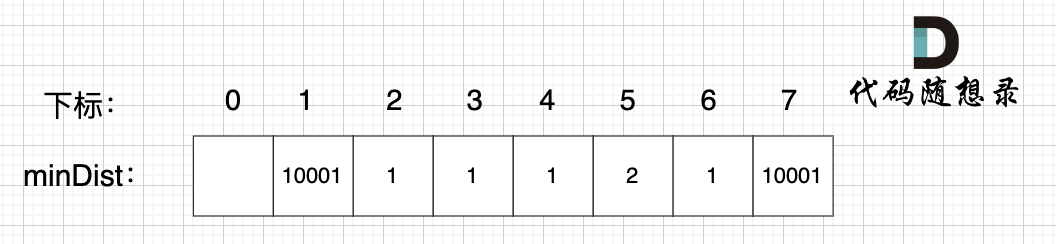
minDist数组是记录了所有非生成树节点距离生成树的最小距离,所以从数组里我们能看出来,非生成树节点4和节点6距离生成树最近。
任选一个加入生成树,我们选节点4(选节点6也行)。
注意,我们根据minDist数组,选取距离生成树最近的节点加入生成树,那么minDist数组里记录的其实也是最小生成树的边的权值(我在图中把权值对应的是哪两个节点也标记出来了)。
如果大家不理解,可以跟着我们下面的讲解,看minDist数组的变化,minDist数组里记录的权值对应的哪条边。
理解这一点很重要,因为最后我们要求最小生成树里所有边的权值和。
2、prim三部曲,第二步:最近节点加入生成树
此时节点1、节点2、节点3、节点4算是最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来更新节点距离最小生成树的距离,如图:

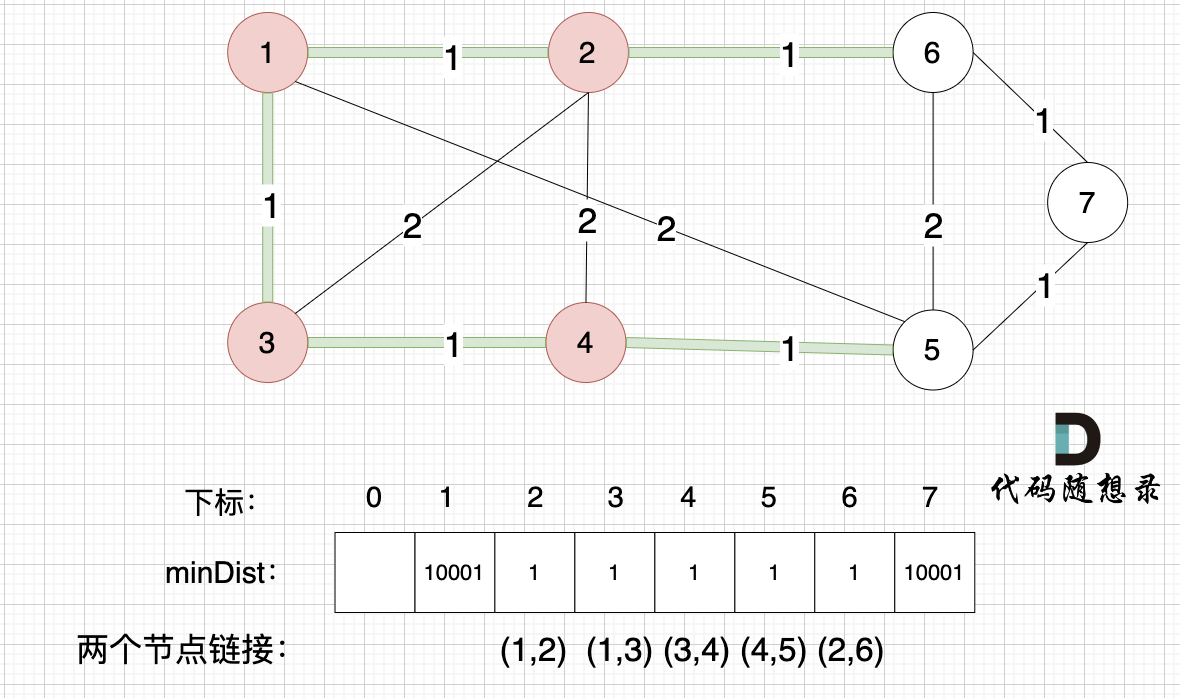
minDist数组已经更新了所有非生成树的节点距离最小生成树(节点1、节点2、节点3、节点4)的距离。
- 节点5和节点4的距离为1,和原先的距离值2小,所以更新minDist[5]为1。
6
1、prim三部曲,第一步:选距离生成树最近节点
继续选距离最小生成树(节点1、节点2、节点3、节点4)最近的非生成树里的节点,只有节点5和节点6。
选节点5(选节点6也可以)加入生成树。
2、prim三部曲,第二步:最近节点加入生成树
节点1、节点2、节点3、节点4、节点5算是最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来更新节点距离最小生成树的距离,如图:

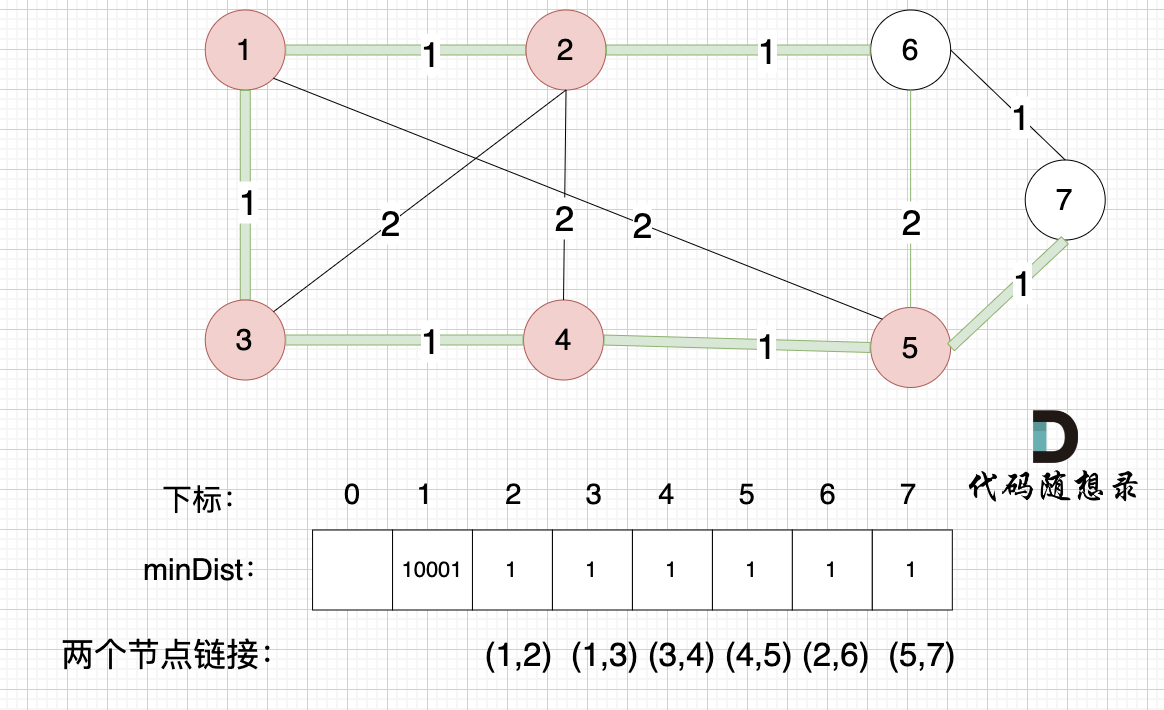
minDist数组已经更新了所有非生成树的节点距离最小生成树(节点1、节点2、节点3、节点4、节点5)的距离。
- 节点6和节点5距离为2,比原先的距离值1大,所以不更新
- 节点7和节点5距离为1,比原先的距离值10001小,更新minDist[7]
7
1、prim三部曲,第一步:选距离生成树最近节点
继续选距离最小生成树(节点1、节点2、节点3、节点4、节点5)最近的非生成树里的节点,只有节点6和节点7。
2、prim三部曲,第二步:最近节点加入生成树
选节点6(选节点7也行,距离一样的)加入生成树。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
节点1、节点2、节点3、节点4、节点5、节点6算是最小生成树的节点,接下来更新节点距离最小生成树的距离,如图:

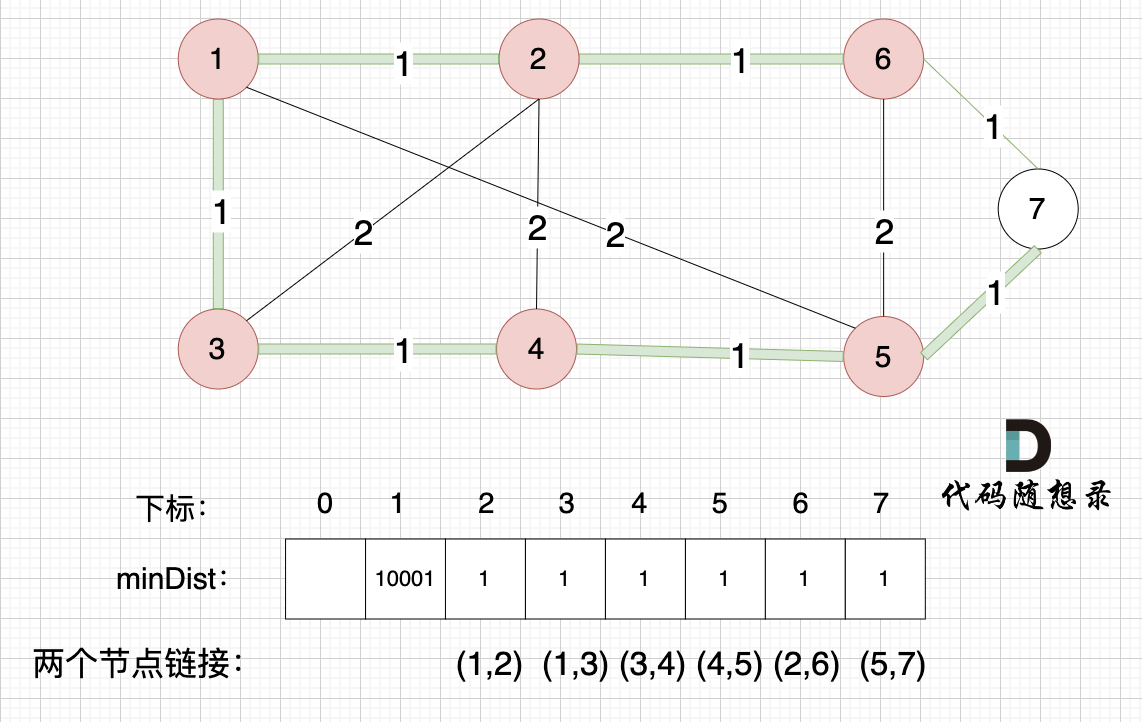
这里就不在重复描述了,大家类推,最后,节点7加入生成树,如图:

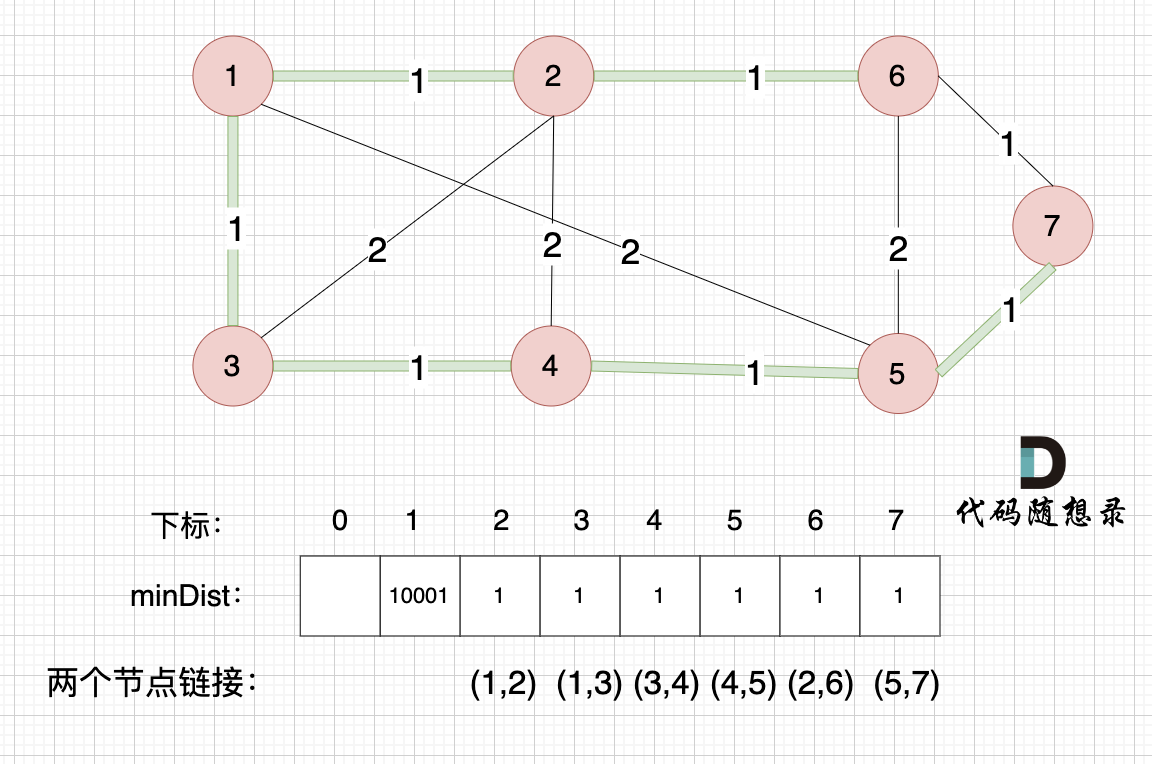
最后
最后我们就生成了一个最小生成树,绿色的边将所有节点链接到一起,并且保证权值是最小的,因为我们在更新minDist数组的时候,都是选距离最小生成树最近的点加入到树中。
讲解上面的模拟过程的时候,我已经强调多次minDist数组是记录了所有非生成树节点距离生成树的最小距离。
最后,minDist数组也就是记录的是最小生成树所有边的权值。
我在图中,特别把每条边的权值对应的是哪两个节点标记出来(例如minDist[7]=1,对应的是节点5和节点7之间的边,而不是节点6和节点7),为了就是让大家清楚,minDist里的每一个值对应的是哪条边。
那么我们要求最小生成树里边的权值总和就是把最后的minDist数组累加一起。
以下代码,我对prim三部曲,做了重点注释,大家根据这三步,就可以透彻理解prim。
Prim代码
- 时间复杂度O(N^2)
- 空间复杂度O(N^2)
1 | def main(): |
Prim记录边
上面讲解的是记录了最小生成树所有边的权值,如果让打印出来最小生成树的每条边呢?或者说要把这个最小生成树画出来呢?
此时我们就需要把最小生成树里每一条边记录下来。
此时有两个问题:
- 1、用什么结构来记录
- 2、如何记录
如果记录边,其实就是记录两个节点就可以,两个节点连成一条边。
如何记录两个节点呢?
我们使用一维数组就可以记录。parent[节点编号] = 节点编号,这样就把一条边记录下来了。(当然如果节点编号非常大,可以考虑使用map)
使用一维数组记录是有向边,不过我们这里不需要记录方向,所以只关注两条边是连接的就行。
parent数组初始化代码:
1 | vector<int> parent(v + 1, -1); |
接下来就是第二个问题,如何记录?
我们再来回顾一下prim三部曲,
- 第一步,选距离生成树最近节点
- 第二步,最近节点加入生成树
- 第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
大家先思考一下,我们是在第几步,可以记录最小生成树的边呢?
在本面上半篇我们讲解过:“我们根据minDist数组,选组距离生成树最近的节点加入生成树,那么minDist数组里记录的其实也是最小生成树的边的权值。”
既然minDist数组记录了最小生成树的边,是不是就是在更新minDist数组的时候,去更新parent数组来记录一下对应的边呢。
所以在prim三部曲中的第三步,更新parent数组,代码如下:
1 | for (int j = 1; j <= v; j++) { |
代码中注释中,我强调了数组指向的顺序很重要。因为不少录友在这里会写成这样: parent[cur] = j 。
这里估计大家会疑惑了,parent[节点编号A] = 节点编号B,就表示A和B相连,我们这里就不用在意方向,代码中为什么只能 parent[j] = cur 而不能 parent[cur] = j 这么写呢?
如果写成 parent[cur] = j,在for循环中,有多个j满足要求,那么 parent[cur] 就会被反复覆盖,因为cur是一个固定值。
举个例子,cur=1,在for循环中,可能就j=2,j=3,j=4都符合条件,那么本来应该记录节点1与节点2、节点3、节点4相连的。
如果 parent[cur] = j 这么写,最后更新的逻辑是 parent[1] = 2, parent[1] = 3, parent[1] = 4,最后只能记录节点1与节点4相连,其他相连情况都被覆盖了。
如果这么写 parent[j] = cur,那就是 parent[2] = 1, parent[3] = 1, parent[4] = 1 ,这样才能完整表示出节点1与其他节点都是链接的,才没有被覆盖。
主要问题也是我们使用了一维数组来记录。
如果是二维数组,来记录两个点链接,例如 parent[节点编号A][节点编号B] = 1 ,parent[节点编号B][节点编号A] = 1,来表示节点A与节点B相连,那就没有上面说的这个注意事项了,当然这么做的话,就是多开辟的内存空间。
Kruskal思路
在上一篇 我们讲解了 prim算法求解 最小生成树,本篇我们来讲解另一个算法:Kruskal,同样可以求最小生成树。
prim 算法是维护节点的集合,而 Kruskal 是维护边的集合。
上来就这么说,大家应该看不太懂,这里是先让大家有这么个印象,带着这个印象在看下文,理解的会更到位一些。
kruscal的思路:
- 边的权值排序,因为要优先选最小的边加入到生成树里
- 遍历排序后的边
- 如果边首尾的两个节点在同一个集合,说明如果连上这条边图中会出现环
- 如果边首尾的两个节点不在同一个集合,加入到最小生成树,并把两个节点加入同一个集合
下面我们画图举例说明kruscal的工作过程。
依然以示例中,如下这个图来举例。


将图中的边按照权值有小到大排序,这样从贪心的角度来说,优先选 权值小的边加入到 最小生成树中。
排序后的边顺序为[(1,2) (4,5) (1,3) (2,6) (3,4) (6,7) (5,7) (1,5) (3,2) (2,4) (5,6)]
(1,2) 表示节点1 与 节点2 之间的边。权值相同的边,先后顺序无所谓。
开始从头遍历排序后的边。
选边(1,2),节点1 和 节点2 不在同一个集合,所以生成树可以添加边(1,2),并将 节点1,节点2 放在同一个集合。

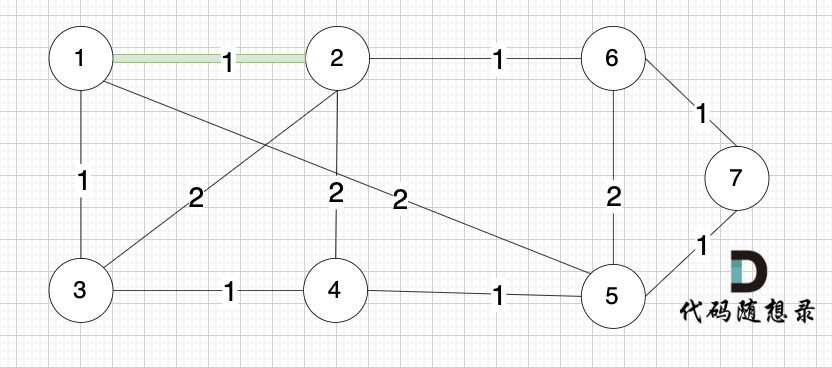
选边(4,5),节点4 和 节点 5 不在同一个集合,生成树可以添加边(4,5) ,并将节点4,节点5 放到同一个集合。


大家判断两个节点是否在同一个集合,就看图中两个节点是否有绿色的粗线连着就行
(这里在强调一下,以下选边是按照上面排序好的边的数组来选择的)
选边(1,3),节点1 和 节点3 不在同一个集合,生成树添加边(1,3),并将节点1,节点3 放到同一个集合。

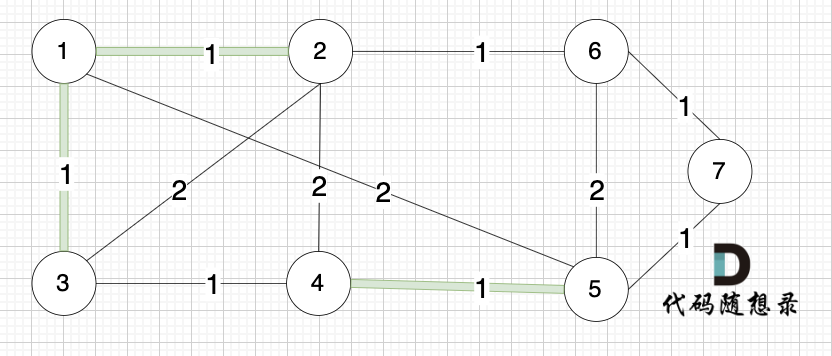
选边(2,6),节点2 和 节点6 不在同一个集合,生成树添加边(2,6),并将节点2,节点6 放到同一个集合。


选边(3,4),节点3 和 节点4 不在同一个集合,生成树添加边(3,4),并将节点3,节点4 放到同一个集合。

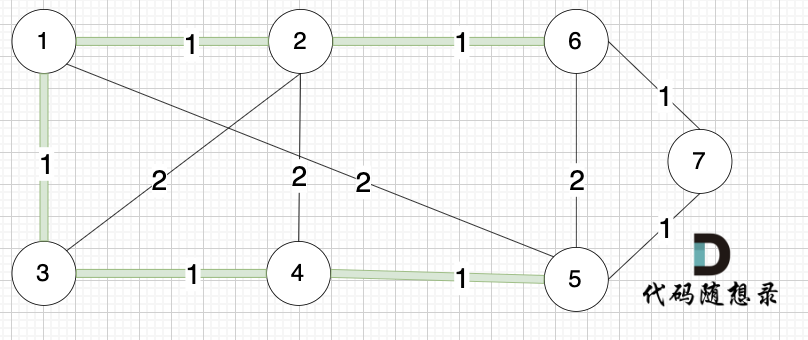
选边(6,7),节点6 和 节点7 不在同一个集合,生成树添加边(6,7),并将 节点6,节点7 放到同一个集合。


选边(5,7),节点5 和 节点7 在同一个集合,不做计算。
选边(1,5),两个节点在同一个集合,不做计算。
后面遍历 边(3,2),(2,4),(5,6) 同理,都因两个节点已经在同一集合,不做计算。
此时 我们就已经生成了一个最小生成树,即:

在上面的讲解中,看图的话 大家知道如何判断 两个节点 是否在同一个集合(是否有绿色的线连在一起),以及如何把两个节点加入集合(就在图中把两个节点连上)
但在代码中,如果将两个节点加入同一个集合,又如何判断两个节点是否在同一个集合呢?
这里就涉及到我们之前讲解的并查集。
我们在并查集开篇的时候就讲了,并查集主要就两个功能:
- 将两个元素添加到一个集合中
- 判断两个元素在不在同一个集合
大家发现这正好符合 Kruskal算法的需求,这也是为什么 我要先讲并查集,再讲 Kruskal。
Kruskal代码
- 时间复杂度:nlogn (快排) + logn (并查集) ,所以最后依然是 nlogn 。n为边的数量。
- 空间复杂度O(n)
1 |
|
不使用结构体代码
1 | class UnionFind: |
Kruskal记录边
如果题目要求将最小生成树的边输出的话,应该怎么办呢?
Kruskal 算法 输出边的话,相对prim 要容易很多,因为 Kruskal 本来就是直接操作边,边的结构自然清晰,不用像 prim一样 需要再将节点连成线输出边 (因为prim是对节点操作,而 Kruskal是对边操作,这是本质区别)
本题中,边的结构为:
1 | struct Edge { |
那么我们只需要找到 在哪里把生成树的边保存下来就可以了。
当判断两个节点不在同一个集合的时候,这两个节点的边就加入到最小生成树, 所以添加边的操作在这里:
1 | vector<Edge> result; // 存储最小生成树的边 |
小技巧
sort以及sorted使用
1 | edges.sort(key = lambda edge: edge.val) |
表示对edge.val作为排序依据(key)








